
Automated Machine Learning – in kurzer Zeit prüfen, ob die Datenbasis für wirtschaftliche Entscheidungen ausreicht
By Autor In Allgemein On 22. Juni 2021
Daten sind das Gold des digitalen Zeitalters! Allerdings müssen Daten, wie jeder Rohstoff, aufbereitet werden. Sind ausreichend Daten im passenden Format vorhanden, kann man durch computergestützte Analysen Muster erkennen und auf deren Basis wirtschaftliche Entscheidungen treffen. Automated Machine Learning ermöglicht es, in kurzer Zeit zu prüfen, ob aus bestehenden Daten ein zuverlässiges Machine Learning Modell entstehen kann.
Machine Learning ist ein Teilbereich der künstlichen Intelligenz. Hierbei erlernen Computer in bereitgestellten Daten bestehende Muster zu erkennen und Zusammenhänge zu finden. Diese erkannten Muster und Zusammenhänge lassen sich dann auf einem neuen, unbekannten Datensatz anwenden, um dann Vorhersagen zu treffen und anschließend Prozesse zu optimieren.
In kurzer Zeit Datenanalysen durchführen und Machine Learning-Modelle erstellen
Die entstehenden Modelle werden dabei durch das Training mit weiteren Daten verbessert, ohne dass dafür explizit programmiert werden muss. Machine Learning wird seit vielen Jahren erfolgreich in Wirtschaft, Forschung und Entwicklung angewandt. Die Analyse und Aufbereitung der erforderlichen Daten galt bis vor Kurzem noch als kompliziert und schwierig. Insbesondere war vor einer Datenanalyse nicht klar, ob in den Daten überhaupt verwertbare Muster vorliegen. Daher scheuten viele Anwender den Aufwand einer Datenanalyse zu betreiben. Denn vor der Analyse ist nicht klar, ob die Datenqualität für die Erstellung von Prognosen ausreichen wird.
Mit Hilfe des Automated Machine Learning, auch AutoML genannt, wird die Analyse deutlich einfacher und schneller als bisher. Automated Machine Learning bezeichnet den Prozess des Automatisierens der zeitaufwändigen, iterativen Aufgaben der Entwicklung eines Machine Learning-Modells. AutoML versetzt Data Scientists, Analysten und Entwickler in die Lage, in kurzer Zeit Datenanalysen durchzuführen und Machine Learning-Modelle zu erstellen.
Beispiel: Ist die Daten-Basis für wirtschaftliche Entscheidungen ausreichend?
Am Beispiel einer Datei mit ca. 33.000 Datensätzen mit Kundeninformationen soll dies demonstriert werden. Die Datei enthält anonyme Beispieldaten von Bankkunden, von denen einige ein Festgeldkonto haben. Es soll geprüft werden, ob die Datenqualität ausreicht, um anhand neuer Daten voraussagen zu können, welcher Kunden bereits ein Festgeldkonto hat oder einrichten wird. Dies ist ein klassischer Fall der Klassifizierung von Kundendaten.
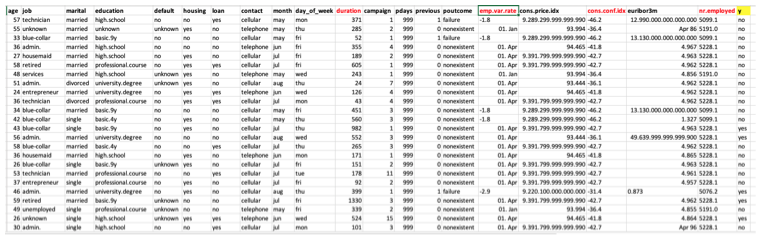
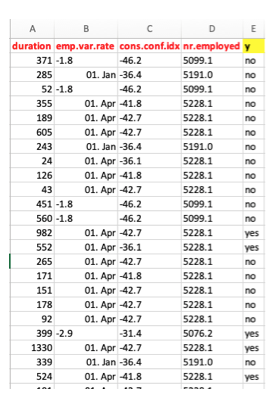
Die Beispiel-Datei hat folgende Spalten:
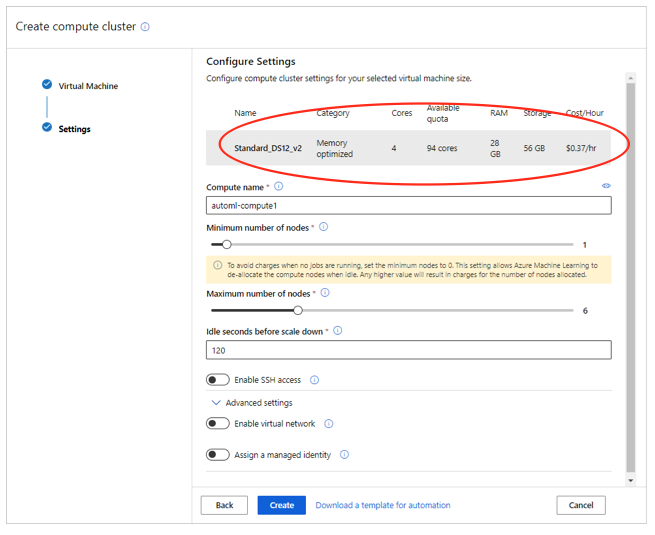
Mit Hilfe des Azure Automated Machine Learnings kann die Datei in die Microsoft-Azure-Cloud hochgeladen werden, die Struktur der Daten geprüft werden und die notwendige Rechenleistung für den Vorgang konfiguriert werden:
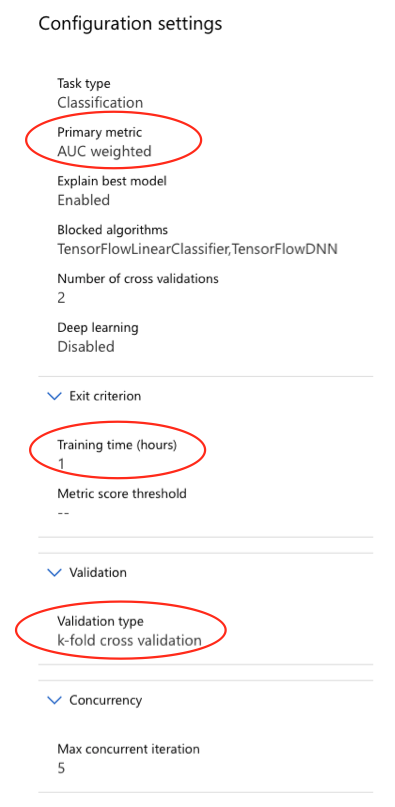
Danach werden die Kriterien festgelegt, wie das entstehende Modell bewertet werden soll und wie lange die Datenanalyse und das Training dauern dürfen. Dafür ist ein kleiner Einblick in die Theorie notwendig: In diesem Beispiel wird die maximale Trainingsdauer auf 1 Stunde festgelegt und das Kreuzvalidierungsverfahren (k-fold-cross-validation) verwendet.
Eine Kreuzvalidierung wird im maschinellen Lernen verwendet, um die Fähigkeiten eines maschinellen Lernmodells auf „unsichtbaren“ Daten abzuschätzen. Das heißt, es wird eine begrenzte Stichprobe verwendet, um abzuschätzen, wie sich das Modell im Allgemeinen verhält, um Vorhersagen über Daten zu treffen, die während des Trainings des Modells nicht verwendet werden.
Als Maß für die Bewertung der Modellgenauigkeit wird das Maß „AUC weighted“ verwendet. Dieses Maß steht für eine Methode, bei der auch unausgeglichene Datensätze bewertet werden können. Das ist in diesem Fall sinnvoll, da in den vorliegenden Daten deutlich mehr Kunden existieren, die kein Festgeldkonto haben, als Kunden mit Festgeldkonto.
Nach Festlegung der Parameter für Analyse und Training kann die Analyse gestartet werden und es muss dann einfach auf die Ergebnisse gewartet werden. In diesem Beispiel sehen sie wie folgt aus:
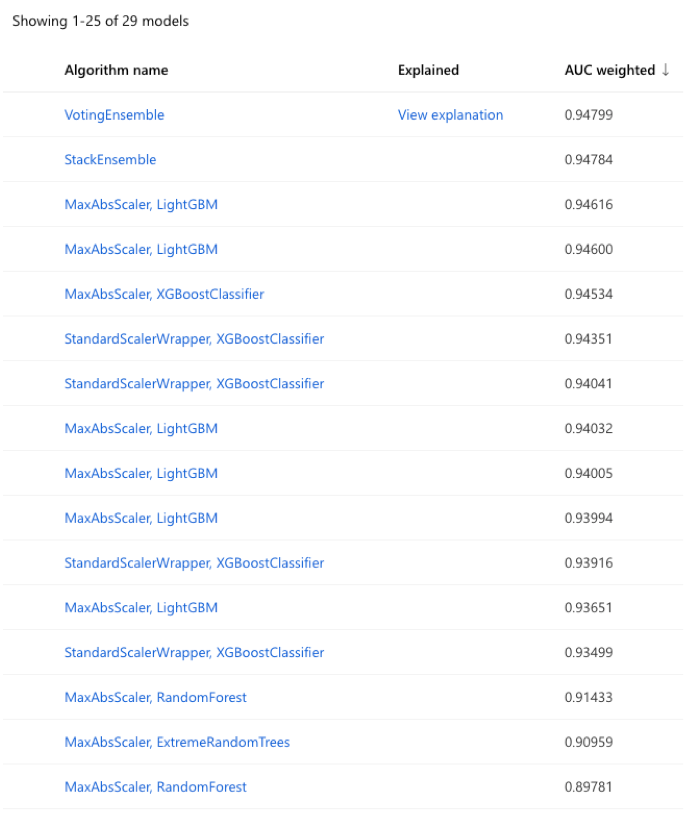
Die durch AutoML verwendeten Algorithmen sind sortiert nach der Genauigkeit, die sie liefern können. Der Algorithmus mit der besten Genauigkeit wird mit einer „Erläuterung“ (Spalte Explained) ausgestattet. Hier wird eine weitere wichtige Frage beantwortet: Welche Informationen haben überhaupt einen Einfluss auf die Güte der Vorhersage? Im nachfolgenden Bild wird erkennbar, dass die Eigenschaften bzw. Spalten „duration“ und „nr.employed“ den größten Einfluss haben und insgesamt vier Eigenschaften (Spalten) ausreichen, um eine Prognose zu treffen. Das heißt, dass die anderen Eigenschaften, also anderen Spalten des Datasets, nicht benötigt werden. Sie müssen daher auch nicht bei einer eventuell angestrebten Verbesserung der Datenqualität weiter aufbereitet werden.
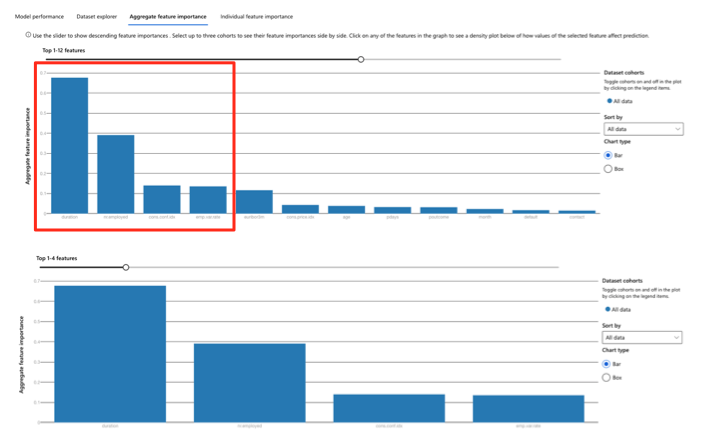
Letztlich würden also nur vier Spalten des Datasets einen wirklichen Einfluss auf die Prognose haben. Das Dataset kann entsprechend reduziert werden.
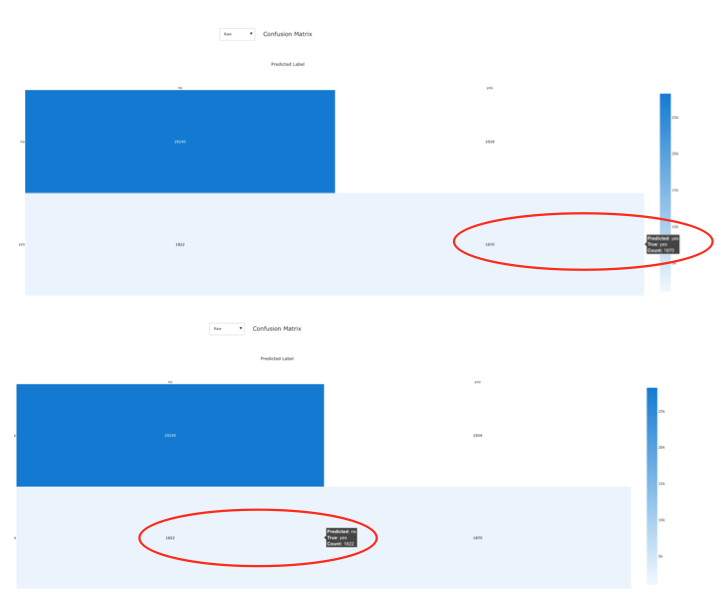
Mit Hilfe der ebenfalls durch AutoML automatisch erstellten Confusion Matrix lässt sich die Prognosegüte bereits ablesen. Im unteren Teil der Confusion Matrix ist dargestellt, wie viele der Kunden ein Festgeldkonto haben und wie viele davon korrekt prognostiziert werden. Da nur ungefähr die Hälfte der Kunden mit Festgeldkonto korrekt prognostiziert wurde, reicht in diesem Beispiel die vorliegende Datenqualität noch nicht aus, um ein Machine Learning Modell mit zuverlässiger Prognosequalität erstellen zu können.
Die Dauer vom Beginn der Analyse bis zur Entscheidung, ob mit den bestehenden Daten eine Prognose möglich ist, betrug in diesem Fall nur ca. 30 Minuten. Mit Automated Machine Learning kann wesentlich schneller und kostengünstiger als mit bisherigen herkömmlichen Methoden einfach mal getestet werden, ob mit bestehenden Daten ein zuverlässiges prognostizierendes Modell trainiert werden kann. Diese Erkenntnis kann als Grundlage für eine wirtschaftliche Entscheidung dienen. Je nachdem, wie groß der Nutzen eines gut funktionierenden Modells wäre, kann nun bewertet werden, ob der weitere Aufwand zur Verbesserung der Datenqualität lohnend ist. Zur Verbesserung der Datenqualität könnte beispielsweise ein Dataset verwendet werden, das deutlich mehr Datensätze enthält oder zusätzliche Eigenschaften (Spalten) enthält, die bisher nicht berücksichtigt wurden. Mit Automated Machine Learning ließe sich ein entsprechend aufbereitetes Dataset ähnlich einfach bewerten.
Alle Produktnamen sind geschützte Marken und Markennamen der jeweiligen Hersteller.